




1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | |
The Horizon
I need to see all the way to the end of time to make progress today.
Sometimes, sea sickness is caused by a sort of confusion. Your inner ear can feel the motion of the world around it, but because it can’t see the outside world, it can’t reconcile its visual input with its proprioceptive input, and the result is nausea.
This is why it helps to see the horizon. If you can see the horizon, your eyes will talk to your inner ears by way of your brain, they will realize that everything is where it should be, and that everything will be OK.
As a result, you’ll stop feeling sick.

I have a sort of motion sickness too, but it’s not seasickness. Luckily, I do not experience nausea due to moving through space. Instead, I have a sort of temporal motion sickness. I feel ill, and I can’t get anything done, when I can’t see the time horizon.
I think I’m going to need to explain that a bit, since I don’t mean the end of the current fiscal quarter. I realize this doesn’t make sense yet. I hope it will, after a bit of an explanation. Please bear with me.
Time management gurus often advise that it is “good” to break up large, daunting tasks into small, achievable chunks. Similarly, one has to schedule one’s day into dedicated portions of time where one can concentrate on specific tasks. This appears to be common sense. The most common enemy of productivity is procrastination. Procrastination happens when you are working on the wrong thing instead of the right thing. If you consciously and explicitly allocate time to the right thing, then chances are you will work on the right thing. Problem solved, right?
Except, that’s not quite how work, especially creative work, works.
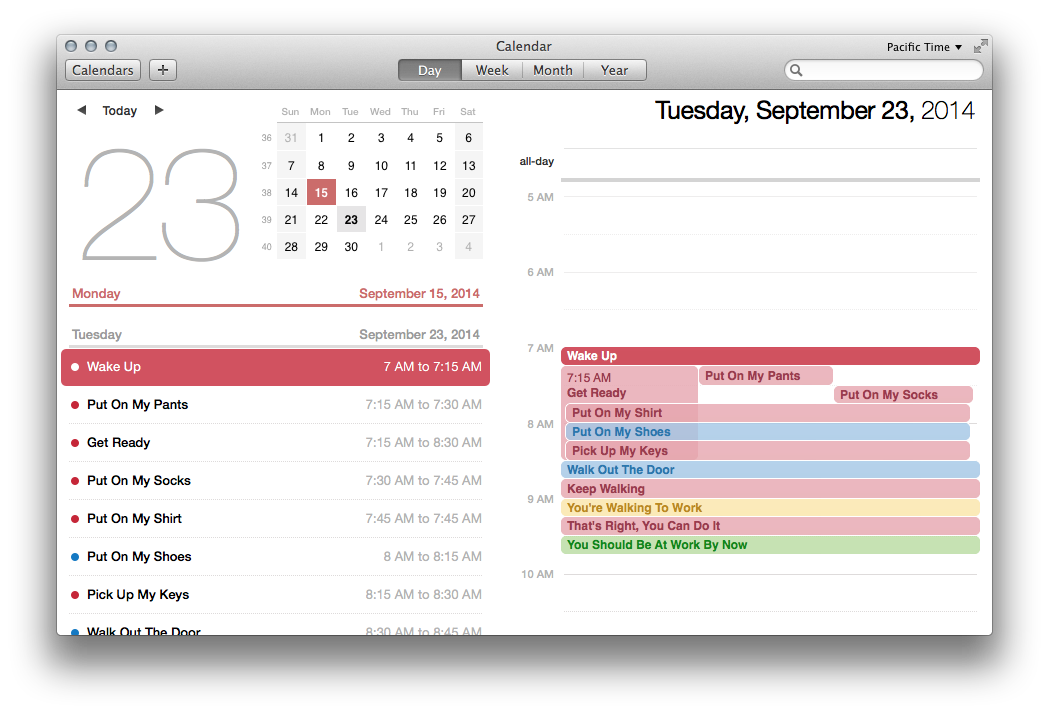
I try to be “good”. I try to classify all of my tasks. I put time on my calendar to get them done. I live inside little boxes of time that tell me what I need to do next. Sometimes, it even works. But more often than not, the little box on my calendar feels like a little cage. I am inexplicably, involuntarily, haunted by disruptive visions of the future that happen when that box ends.
Let me give you an example.
Let’s say it’s 9AM Monday morning and I have just arrived at work. I can see that at 2:30PM, I have a brief tax-related appointment. The hypothetical person doing my hypothetical taxes has an office that is a 25 minute hypothetical walk away, so I will need to leave work at 2PM sharp in order to get there on time. The appointment will last only 15 minutes, since I just need to sign some papers, and then I will return to work. With a 25 minute return trip, I should be back in the office well before 4, leaving me plenty of time to deal with any peripheral tasks before I need to leave at 5:30. Aside from an hour break at noon for lunch, I anticipate no other distractions during the day, so I have a solid 3 hour chunk to focus on my current project in the morning, an hour from 1 to 2, and an hour and a half from 4 to 5:30. Not an ideal day, certainly, but I have plenty of time to get work done.
The problem is, as I sit down in front of my nice, clean, empty text editor to sketch out my excellent programming ideas with that 3-hour chunk of time, I will immediately start thinking about how annoyed I am that I’m going to get interrupted in 5 and a half hours. It consumes my thoughts. It annoys me. I unconsciously attempt to soothe myself by checking email and getting to a nice, refreshing inbox zero. Now it’s 9:45. Well, at least my email is done. Time to really get to work. But now I only have 2 hours and 15 minutes, which is not as nice of an uninterrupted chunk of time for a deep coding task. Now I’m even more annoyed. I glare at the empty window on my screen. It glares back. I spend 20 useless minutes doing this, then take a 10-minute coffee break to try to re-set and focus on the problem, and not this silly tax meeting. Why couldn’t they just mail me the documents? Now it’s 10:15, and I still haven’t gotten anything done.
By 10:45, I manage to crank out a couple of lines of code, but the fact that I’m going to be wasting a whole hour with all that walking there and walking back just gnaws at me, and I’m slogging through individual test-cases, mechanically filling docstrings for the new API and for the tests, and not really able to synthesize a coherent, holistic solution to the overall problem I’m working on. Oh well. It feels like progress, albeit slow, and some days you just have to play through the pain. I struggle until 11:30 at which point I notice that since I haven’t been able to really think about the big picture, most of the test cases I’ve written are going to be invalidated by an API change I need to make, so almost all of the morning’s work is useless. Damn it, it’s 2014, I should be able to just fill out the forms online or something, having to physically carry an envelope with paper in it ten blocks is just ridiculous. Maybe I could get my falcon to deliver it for me.
It’s 11:45 now, so I’m not going to get anything useful done before lunch. I listlessly click on stuff on my screen and try to relax by thinking about my totally rad falcon until it’s time to go. As I get up, I glance at my phone and see the reminder for the tax appointment.
Wait a second.
The appointment has today’s date, but the subject says “2013”. This was just some mistaken data-entry in my calendar from last year! I don’t have an appointment today! I have nowhere to be all afternoon.
For pointless anxiety over this fake chore which never even actually happened, a real morning was ruined. Well, a hypothetical real morning; I have never actually needed to interrupt a work day to walk anywhere to sign tax paperwork. But you get the idea.
To a lesser extent, upcoming events later in the week, month, or even year bother me. But the worst is when I know that I have only 45 minutes to get into a task, and I have another task booked up right against it. All this trying to get organized, all this carving out uninterrupted time on my calendar, all of this trying to manage all of my creative energies and marshal them at specific times for specific tasks, annihilates itself when I start thinking about how I am eventually going to have to stop working on the seemingly endless, sprawling problem set before me.
The horizon I need to see is the infinite time available before me to do all the thinking I need to do to solve whatever problem has been set before me. If I want to write a paragraph of an essay, I need to see enough time to write the whole thing.
Sometimes - maybe even, if I’m lucky, increasingly frequently - I manage to fool myself. I hide my calendar, close my eyes, and imagine an undisturbed millennium in front of my text editor ... during which I may address some nonsense problem with malformed utf-7 in mime headers.
... during which I can complete a long and detailed email about process enhancements in open source.
... during which I can write a lengthy blog post about my productivity-related neuroses.
I imagine that I can see all the way to the distant horizon at the end of time, and that there is nothing between me and it except dedicated, meditative concentration.
That is on a good day. On a bad day, trying to hide from this anxiety manifests itself in peculiar and not particularly healthy ways. For one thing, I avoid sleep. One way I can always extend the current block of time allocated to my current activity is by just staying awake a little longer. I know this is basically the wrong way to go about it. I know that it’s bad for me, and that it is almost immediately counterproductive. I know that ... but it’s almost 1AM and I’m still typing. If I weren’t still typing right now, instead of sleeping, this post would never get finished, because I’ve spent far too many evenings looking at the unfinished, incoherent draft of it and saying to myself, "Sure, I’d love to work on it, but I have a dentist’s appointment in six months and that is going to be super distracting; I might as well not get started".
Much has been written about the deleterious effects of interrupting creative thinking. But what interrupts me isn’t an interruption; what distracts me isn’t even a distraction. The idea of a distraction is distracting; the specter of a future interruption interrupts me.
This is the part of the article where I wow you with my life hack, right? Where I reveal the one weird trick that will make productivity gurus hate you? Where you won’t believe what happens next?
Believe it: the surprise here is that this is not a set-up for some choice productivity wisdom or a sales set-up for my new book. I have no idea how to solve this problem. The best I can do is that thing I said above about closing my eyes, pretending, and concentrating. Honestly, I have no idea even if anyone else suffers from this, or if it’s a unique neurosis. If a reader would be interested in letting me know about their own experiences, I might update this article to share some ideas, but for now it is mostly about sharing my own vulnerability and not about any particular solution.
I can share one lesson, though. The one thing that this peculiar anxiety has taught me is that productivity “rules” are not revealed divine truth. They are ideas, and those ideas have to be evaluated exclusively on the basis of their efficacy, which is to say, on the basis of how much stuff that you want to get done that they help you get done.
For now, what I’m trying to do is to un-clench the fearful, spasmodic fist in my mind that gripping the need to schedule everything into these small boxes and allocate only the time that I “need” to get something specific done.
Maybe the only way I am going to achieve anything of significance is with opaque, 8-hour slabs of time with no more specific goal than “write some words, maybe a blog post, maybe some fiction, who knows” and “do something work-related”. As someone constantly struggling to force my own fickle mind to accomplish any small part of my ridiculously ambitions creative agenda, it’s really hard to relax and let go of anything which might help, which might get me a little further a little faster.
Maybe I should be trying to schedule my time into tiny little blocks. Maybe I’m just doing it wrong somehow and I just need to be harder on myself, madder at myself, and I really can get the blood out of this particular stone.
Maybe it doesn’t matter all that much how I schedule my own time because there’s always some upcoming distraction that I can’t control, and I just need to get better at meditating and somehow putting them out of my mind without really changing what goes on my calendar.
Maybe this is just as productive as I get, and I’ll still be fighting this particular fight with myself when I’m 80.
Regardless, I think it’s time to let go of that fear and try something a little different.
Techniques for Actually Distributed Development with Git
It's all very wibbly wobbly and versiony wersiony.
The Setup
I have a lot of computers. Sometimes I'll start a project on one computer and
get interrupted, then later find myself wanting to work on that same project,
right where I left off, on another computer. Sometimes I'm not ready to
publish my work, and I might still want to rebase it a few times (because if
you're not arbitrarily rewriting history all the time you're not really using
Git) so I don't want to push to @{upstream} (which is how you say "upstream"
in Git).
I would like to be able to use Git to synchronize this work in progress between multiple computers. I would like to be able to easily automate this synchronization so that I don’t have to remember any special steps to sync up; one of the most focused times that I have available to get coding and writing work done is when I’m disconnected from the Internet, on a cross-country train or a plane trip, or sitting near a beach, for 5-10 hours. It is very frustrating to realize only once I’m settled in and unable to fetch the code, that I don’t actually have it on my laptop because I was last doing something on my desktop. I would particularly like to be able to that offline time to resolve tricky merge conflicts; if there are two versions of a feature, I want to have them both available locally while I'm disconnected.
Completely Fake, Made-Up History That Is A Lie
As everyone knows, Git is a centralized version control system created by the popular website GitHub as a command-line client for its "forking" HTML API. Alternate central Git authorities have been created by other startups following in the wave following GitHub's success, such as BitBucket and GitLab.
It may surprise many younger developers to know that when GitHub first created Git, it was originally intended to be a distributed version control system, where it was possible to share code with no particular central authority!
Although the feature has been carefully hidden from the casual user, with a bit of trickery you can enable re-enable it!
Technique 0: Understanding What's Going On
It's a bit confusing to have to actually set up multiple computers to test these things, so one useful thing to understand is that, to Git, the place you can fetch revisions from and push revisions to is a repository. Normally these are identified by URLs which identify hosts on the Internet, but you can also just indicate a path name on your computer. So for example, we can simulate a "network" of three computers with three clones of a repository like this:
1 2 3 4 5 6 7 8 | |
This creates three separate repositories. But since they're not clones of each other, none of them have any remotes, and none of them can push or pull from each other. So how do we teach them about each other?
1 2 3 4 5 6 7 8 9 | |
Now, you can go into a and type git fetch --all and it will fetch from b
and c, and similarly for git fetch --all in b and c.
To turn this into a practical multiple-machine scenario, rather than specifying
a path like ../b, you would specify an SSH URL as your remote URL, and turn
SSH on on each of your machines ("Remote Login" in the Sharing preference pane
on the mac, if you aren't familiar with doing that on a mac).
So, for example, if you have a home desktop tweedledee and a work laptop
tweedledum, you can do something like this:
1 2 3 4 5 6 7 8 | |
I don't know the names of the hosts on your network. So, in order to make it possible for you to follow along exactly, I'll use the repositories that I set up above, with path-based remotes, in the following examples.
Technique 1 (Simple): Always Only Fetch, Then Merge
Git repositories are pretty boring without any commits, so let's create a commit:
1 2 3 4 5 6 7 | |
Now on our "computers" b and c, we can easily retrieve this commit:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
If we make a change on b, we can easily pull it into a as well.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
This technique is quite workable, except for one minor problem.
The Minor Problem
Let's say you're sitting on your laptop and your battery is about to die. You want to push some changes from your laptop to your desktop. Your SSH key, however, is plugged in to your laptop. So you just figure you'll push from your laptop to your desktop. Unfortunately, if you try, you'll see something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
While you're reading this, you fail your will save and become too bored to look at a computer any more.
Too late, your battery is dead! Hopefully you didn't lose any work.
In other words: sometimes it's nice to be able to push changes as well.
Technique 1.1: The Manual Workaround
The problem that you're facing here is that b has its master branch
checked out, and is therefore rejecting changes to that branch. Your
commits have actually all been "uploaded" to b, and are present in that
repository, but there is no branch pointing to them. Doing either of those
configuration things that Git warns you about in order to force it to allow it
is a bad idea, though; if your working tree and your index and your your
commits don't agree with each other, you're just asking for trouble.
Git is confusing enough as it is.
In order work around this, you can just push your changes in master on a to
a diferent branch on b, and then merge it later, like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
This works just fine, you just always have to manually remember which branches you want to push, and where, and where you're pushing from.
Technique 2: Push To Reverse Pull To Remote Remotes
The astute reader will have noticed at this point that git already has a way
of tracking "other places that changes came from", they're called remotes! And
in fact b already has a remote called a pointing at ../a. Once you're
sitting in front of your b computer again, wouldn't you rather just have
those changes already in the a remote, instead of in some branch you have to
specifically look for?
What if you could just push your branches from a into that remote? Well,
friend, I'm here today to tell you you can.
First, head back over to a...
1 | |
And now, all you need is this entirely straightforward and obvious command:
1 | |
and now, when you git push b from a, you will push those branches into b's
"a" remote, as if you had done git fetch a while in b.
1 2 3 4 | |
So, if we make more changes:
1 2 3 4 | |
we can push them to b...
1 2 3 4 5 6 | |
and when we return to b...
1 | |
there's nothing to fetch, it's all been pre-fetched already, so
1 | |
produces no output.
But there is some stuff to merge, so if we took b on a plane with us:
1 2 3 4 5 | |
we can merge those changes in whenever we please!
More importantly, unlike the manual-syncing solution, this allows us to push
multiple branches on a to b without worrying about conflicts, since the a
remote on b will always only be updated to reflect the present state of a
and should therefore never have conflicts (and if it does, it's because you
rewrote history and you should be able to force push with no particular
repercussions).
Generalizing
Here's a shell function which takes 2 parameters, "here" and "there". "here" is the name of the current repository - meaning, the name of the remote in the other repository that refers to this one - and "there" is the name of the remote which refers to another repository.
1 2 3 4 5 6 | |
In the above example, we could have used this shell function like so:
1 2 | |
I now use this all the time when I check out a repository on multiple machines for the first time; I can then always easily push my code to whatever machine I’m going to be using next.
I really hope at least one person out there has equally bizarre usage patterns of version control systems and finds this post useful. Let me know!
Acknowledgements
Thanks very much to Tom Prince for the information that lead to this post being worth sharing, and Jenn Schiffer for teaching me that it is OK to write jokes sometimes, except about javascript which is very serious and should not be made fun of ever.
Some things, one writes because one has something one wants the world to know.
Some things, one writes because, despite one’s better judgment, one can’t help it.
This is one of the latter type.
I have a recurring dream. I mean this in the most literal sense possible. I do not mean that I have an aspiration, or a hope. This is literally a dream that I’ve had, while I was asleep, multiple times. I’m not really sure why, since the apparent stimulus that this dream is responding to is many, many years in my past. Nevertheless, I have had it 3 or 4 times now.
It’s a movie trailer.
There’s a man driving a pickup truck along a highway near open plains.
Intercut are images of him driving a tractor over an apparently endless field, shot from a fixed 3rd-person perspective behind the tractor, driving towards the horizon. Close up of his face. He looks bored, resigned.

He sees a falling star streaking down from the sky. As he watches, there’s a roaring noise, and a boom, and it crashes down into an adjacent field.
Cut to him cautiously exploring the crash site. There’s an object in the middle of the crash site, still glowing red hot. It’s a strange shape; conical, about a meter long, but with an indentation on its side and various protrusions, one of which looks like a human-sized handle.
Another cut, now he’s inside the truck again, and we can see that the object is under a tarp in the back of the truck.
Now he’s in his garage. He’s wearing a red work shirt and blue jeans. The object is hoisted up on a lift, and he’s walking around it, examining it. A prolonged sequence of him trying to cut it open with a plasma arc cutter, then wiping off the smudge to reveal it’s still shiny.
Finally, he lowers the lift, but as it goes towards the ground, the object beeps and stops dropping, at about waist height. It slowly rotates, swiveling to point towards the open garage door.
He walks over to the object and stands next to it, his hip near the indentation in its side, and he reaches out to grab the handle. The machine makes a powering-on whine and more protrusions start folding out of its sides; he yanks his hand back like he’s been burned, and it folds back into itself. More cautiously this time, he reaches out to grab the handle.
The machine’s tip opens like a claw, revealing a central spike surrounded by a bunch of curved radiating antennae. Sparks start shooting between the antennae and the spike, charging it. A view screen unfolds, initially displaying a targeting reticle pointed out of his garage door, then switching to text in an alien language. A grainy voice comes out of speakers in the side of the machine, initially speaking the alien language. Then the language on the screen switches to Japanese, then to French, then to German, and finally to English. In large, flashing, block letters, it reads, and the grainy voice from its speakers says, simply:
GET READY
Before the man has a chance to the react, the indentation in the side of the machine extrudes several parts of a metallic harness which surround his body. A thruster on the back part of the machine starts glowing a dull red color, and then the machine (with the man in tow) shoots out of his garage.
Initially, he is running furiously to keep up. He trips over a rock in the road, but the harness allows him to sort of gyroscopically spin while still attached to the machine, and then right himself again. Eventually he pulls back on the handle and he’s flying through the air, and then the protrusion on the nose of the machine shoots a beam in front of him and opens a portal, which he then flies through.

The machine says “Welcome to the fantasy zone.” and then “Get ready!” again, and then we see a montage of him flying over alien landscapes, primarily plains checkered in garish primary colors, shooting giant plasma bullets out of the nose of the weapon at trees, tiny fighter jets, rocks, and basically anything that gets in his way. There are scenes of him talking to giant one-eyed mammoths, and a teaser-trailer shot of giant, horrible looking two-headed dragons.
COMING THIS SUMMER: SPACE HARRIER, THE MOTION PICTURE.
Then I wake up.
Sega: please, please get someone to make this movie. The dream is only ever the trailer, and I really want to see how it ends.

Lots of folks are very excited about
the Tulip project,
recently released as the asyncio standard library module in Python 3.4.
This module is potentially exciting for two reasons:
- It provides an abstract, language-blessed, standard interface for event-driven network I/O. This means that instead of every event-loop library out there having to implement everything in terms of every other event-loop library’s ideas of how things work, each library can simply implement adapters from and to those standard interfaces. These interfaces substantially resemble the abstract interfaces that Twisted has provided for a long time, so it will be relatively easy for us to adapt to them.
- It provides a new, high-level
coroutine scheduler,
providing a slightly cleaned-up syntax (
returnworks!) and more efficient implementation (no need for a manual trampoline, it’s built straight into the language runtime viayield from) of something likeinlineCallbacks.
However, in their understandable enthusiasm, some observers of Tulip’s progress – links withheld to protect the guilty – have been forecasting Twisted’s inevitable death, or at least its inevitable consignment to the dustbin of “legacy code”.
At first I thought that this was just sour grapes from people who disliked Twisted for some reason or other, but then I started hearing this as a concern from users who had enjoyed using Twisted.
So let me reassure you that the idea that Twisted is going away is totally wrong. I’ll explain how.
The logic that leads to this belief seems to go like this:
Twisted is an async I/O thing,
asynciois an async I/O thing. Therefore they are the same kind of thing. I only need one kind of thing in each category of thing. Therefore I only need one of them, and the “standard” one is probably the better one to depend on. So I guess nobody will need Twisted any more!
The problem with this reasoning is that “an async I/O thing” is about as specific as “software that runs on a computer”. After all, Firefox is also “an async I/O thing” but I don’t think that anyone is forecasting the death of web browsers with the release of Python 3.4.
Which Is Better: OpenOffice or Linux?
Let’s begin with the most enduring reason that Twisted is not going anywhere
any time soon. asyncio is an implementation of a transport layer and an
event-loop API; it can move bytes into and out of your application, it can
schedule timed calls to happen at some point in the future, and it can start
and stop. It’s also an implementation of a coroutine scheduler; it can
interleave apparently sequential logic with explicit
yield points. There are also some experimental third-party extension modules
available, including
an event-driven HTTP server and client,
and the community keeps building more stuff.
In other words, asyncio is a kernel for event-driven programming, with some applications starting to be developed.
Twisted is also an implementation of a transport layer and an event-loop API.
It’s also got a coroutine scheduler, in the form of inlineCallbacks.
Twisted is also a production-quality event-driven HTTP server and client including its own event-driven templating engine, with third-party HTTP addons including server microframeworks, high-level client tools, API construction kits, robust, two-way browser communication, and automation for usually complex advanced security features.
Twisted is also an SSH client, both an API and a command-line replacement for OpenSSH. It’s also an SSH server which I have heard some people think is OK to use in production. Again, the SSH server is both an API and again as a daemon replacement for OpenSSH. (I'd say "drop-in replacement" except that neither the client nor server can parse OpenSSH configuration files. Yet.)
Twisted also has a native, symmetric event-driven message-passing protocol designed to be easy to implement in other languages and environments, making it incredibly easy to develop a custom protocol to propagate real-time events through multiple components; clients, servers, embedded devices, even web browsers.
Twisted is also a chat server you can deploy with one shell command. Twisted is also a construction kit for IRC bots. Twisted is also an XMPP client and server library. Twisted is also a DNS server and event-driven DNS client. Twisted is also a multi-protocol integrated authentication API. Twisted is also a pluggable system for creating transports to allow for third-party transport components to do things like allow you to run as a TOR hidden service with a single command-line switch and no modifications to your code.
Twisted is also a system for processing streams of geolocation data including from real hardware devices, via serial port support.
Twisted also natively implements GUI integration support for the Mac, Windows, and Linux.
I could go on.
If I were to include what third-party modules are available as well, I could go on at some considerable length.
The point is, while Twisted also has an existing kernel – largely compatible,
at a conceptual level at least, with the way asyncio was designed – it also
has a huge suite of functionality, both libraries and applications. Twisted is
OpenOffice to asyncio’s Linux.
Of course this metaphor isn’t perfect. Of course the
nascent asyncio community will come to supplant some
of these things with other third-party tools. Of course there will be some
duplication and some competing projects. That’s normal, and even healthy. But
this is not a winner-take all existential Malthusian competition. Being able
to leverage the existing functionality within the Twisted and Tornado
ecosystems – and vice versa, allowing those ecosystems to leverage new things
written with asyncio – was not an accident, it was an
explicit, documented design goal of asyncio.
Now And Later
Python 3 is the future of Python.
While Twisted still has
a ways to go to finish
porting to Python 3, you will be able to pip install the portions that
already work as of the upcoming 14.0 release (which should be out any day now).
So contrary to some incorrect impressions I’ve heard, the Twisted team is
working to support that future.
(One of the odder things that I’ve heard people say about asyncio is that now
that Python 3 has asyncio, porting Twisted is now unnecessary. I'm not sure
that Twisted is necessary per se – our planet has been orbiting that
cursed orb for over 4 billion
years without Twisted’s help – but if you want to create an XMPP to IMAP
gateway in Python it's not clear to me how having just asyncio is going to
help.)
However, while Python 3 may be the future of Python, right now it is sadly just the future, and not the present.
If you want to use asyncio today, that means foregoing the significant
performance benefits of pypy. (Even the beta releases of
pypy3, which still routinely segfault for me, only support the language version
3.2, so no “yield from” syntax.) It means cutting yourself off from a
significant (albeit gradually diminishing) subset
of available Python libraries.
You could use the Python 2 backport of Tulip,
Trollius, but since idiomatic
Tulip code relies heavily on the new yield from syntax, it’s possible to
write code that works on both,
but not idiomatically.
Trollius actually works on Python 3 as well, but then you miss out on one of
the real marquee features of Tulip.
Also, while Twisted has a
strict compatibility policy,
asyncio is still marked as having
provisional status,
meaning that unlike the rest of the standard library, its API may change
incompatibly in the next version of Python. While it’s unlikely that this will
mean major changes for asyncio, since Python 3.4 was just released, it will
be in this status for at least the next 18 months, until Python 3.5 arrives.
As opposed to the huge laundry list of functionality above, all of these
reasons will eventually be invalidated, hopefully sooner rather than later; if
these were the only reasons that Twisted were going to stick around, I would
definitely be worried. However, they’re still reasons why today, even if you
only need the pieces of an asynchronous I/O system that the new asyncio
module offers, you still might want to choose Twisted’s core event loop APIs.
Keep in mind that using Twisted today doesn’t cut you off from using asyncio
in the future: far from it, it makes it likely that you will be able to easily
integrate whatever new asyncio code you write once you adopt it. Twisted’s
goal, as Laurens van Houtven eloquently explained it this year in a PyCon talk,
is to
work with absolutely everything,
and that very definitely includes asyncio and Python 3.
My Own Feelings
I feel like asyncio is a step forward for Python, and, despite the dire
consequences some people seemed to expect, a tremendous potential benefit to
Twisted.
For years, while we – the Twisted team – were trying to build the “engine of your Internet”, we were also having to make a constant, tedious sales pitch for the event-driven model of programming. Even today, we’re still stuck writing rambling, digressive rants explaining why you might not want three threads for every socket, giving conference talks where we try to trick the audience into writing a callback, and trying to explain basic stuff about networking protocols to an unreceptive, frustrated audience.
This audience was unreceptive because the broader python community has been less than excited about event-driven networking and cooperative task coordination in general. It’s a vicious cycle: programmers think events look “unpythonic”, so they write their code to block. Other programmers then just want to make use of the libraries suitable to their task, and they find ones which couple (blocking) I/O together with basic data-processing tasks like parsing.
Oddly enough, I noticed a drop in the frequency that I needed to have this sort of argument once node.js started to gain some traction. Once server-side Python programmers started to hear all the time about how writing callbacks wasn't a totally crazy thing to be doing on the server, there was a whole other community to answer their questions about why that was.
With the advent of asyncio, there is functionality available in the standard
library to make event-driven implementations of things immediately useful.
Perhaps even more important this functionality, there is guidance on how to
make your own event-driven stuff. Every module that is written using asyncio
rather than io is a module that at least can be made to work natively
within Twisted without rewriting or monkeypatching it.
In other words, this has shifted the burden of arguing that event-driven programming is a worthwhile thing to do at all from Twisted to a module in the language’s core.
While it’ll be quite a while before most Python programmers are able to use
asyncio on a day to day basis its mere existence justifies the conceptual
basis of Twisted to our core consituency of Python programmers who want to put
an object on a network. Which, in turn, means that we can dedicate more of our
energy to doing cool stuff with Twisted, and we can dedicate more of the time
we spend educating people to explaining how to do cool things with all the
crazy features Twisted provides rather than explaining why you would even want
to write all these weird callbacks in the first place.
So Tulip is a good thing for Python, a good thing for Twisted, I’m glad it exists, and it doesn't make me worried at all about Twisted’s future.
Quite the opposite, in fact.