




Several years ago at O’Reilly’s Software Architecture conference, within a comprehensive talk on refactoring “Technical Debt: A Masterclass”, r0ml1 presented a concept that I think should be highlighted.
If you have access to O’Reilly Safari, I think the video is available there, or you can get the slides here. It’s well worth watching in its own right. The talk contains a lot of hard-won wisdom from a decades-long career, but in slides 75-87, he articulates a concept that I believe resolves the perennial pendulum-swing between microservices and monoliths that we see in the Software as a Service world.
I will refer to this concept as “the bilithification strategy”.
Background
Personally, I have long been a microservice skeptic. I would generally articulate this skepticism in terms of “YAGNI”.
Here’s the way I would advise people asking about microservices before encountering this concept:
Microservices are often adopted by small teams due to their advertised benefits. Advocates from very large organizations—ones that have been very successful with microservices—frequently give talks claiming that microservices are more modular, more scalable, and more fault-tolerant than their monolithic progenitors. But these teams rarely appreciate the costs, particularly the costs for smaller orgs. Specifically, there is a fixed operational marginal cost to each new service, and a fairly large fixed operational overhead to the infrastructure for an organization deploying microservices in at all.
With a large enough team, the operational cost is easy to absorb. As the overhead is fixed, it trends towards zero as your total team size and system complexity trend towards infinity. Also, in very large teams, the enforced isolation of components in separate services reduces complexity. It does so specifically intentionally causing the software architecture to mirror the organizational structure of the team that deploys it. This — at the cost of increased operational overhead and decreased efficiency — allows independent parts of the organization to make progress independently, without blocking on each other. Therefore, in smaller teams, as you’re building, you should bias towards building a monolith until the complexity costs of the monolith become apparent. Then you should build the infrastructure to switch to microservices.
I still stand by all of this. However, it’s incomplete.
What does it mean to “switch to microservices”?
The biggest thing that this advice leaves out is a clear understanding of the “micro” in “microservice”. In this framing, I’m implicitly understanding “micro” services to be services that are too small — or at least, too small for your team. But if they do work for large organizations, then at some point, you need to have them. This leaves open several questions:
- What size is the right size for a service?
- When should you split your monolith up into smaller services?
- Wait, how do you even measure “size” of a service? Lines of code? Gigabytes of memory? Number of team members?
In a specific situation I could probably look at these questions for that situation, and make suggestions as to the appropriate course of action, but that’s based largely on vibes. There’s just a lot of drawing on complex experiences, not a repeatable pattern that a team could apply on their own.
We can be clear that you should always start with a monolith. But what should you do when that’s no longer working? How do you even tell when it’s no longer working?
Bilithification
Every codebase begins as a monolith. That is a single (mono) rock (lith). Here’s what it looks like.
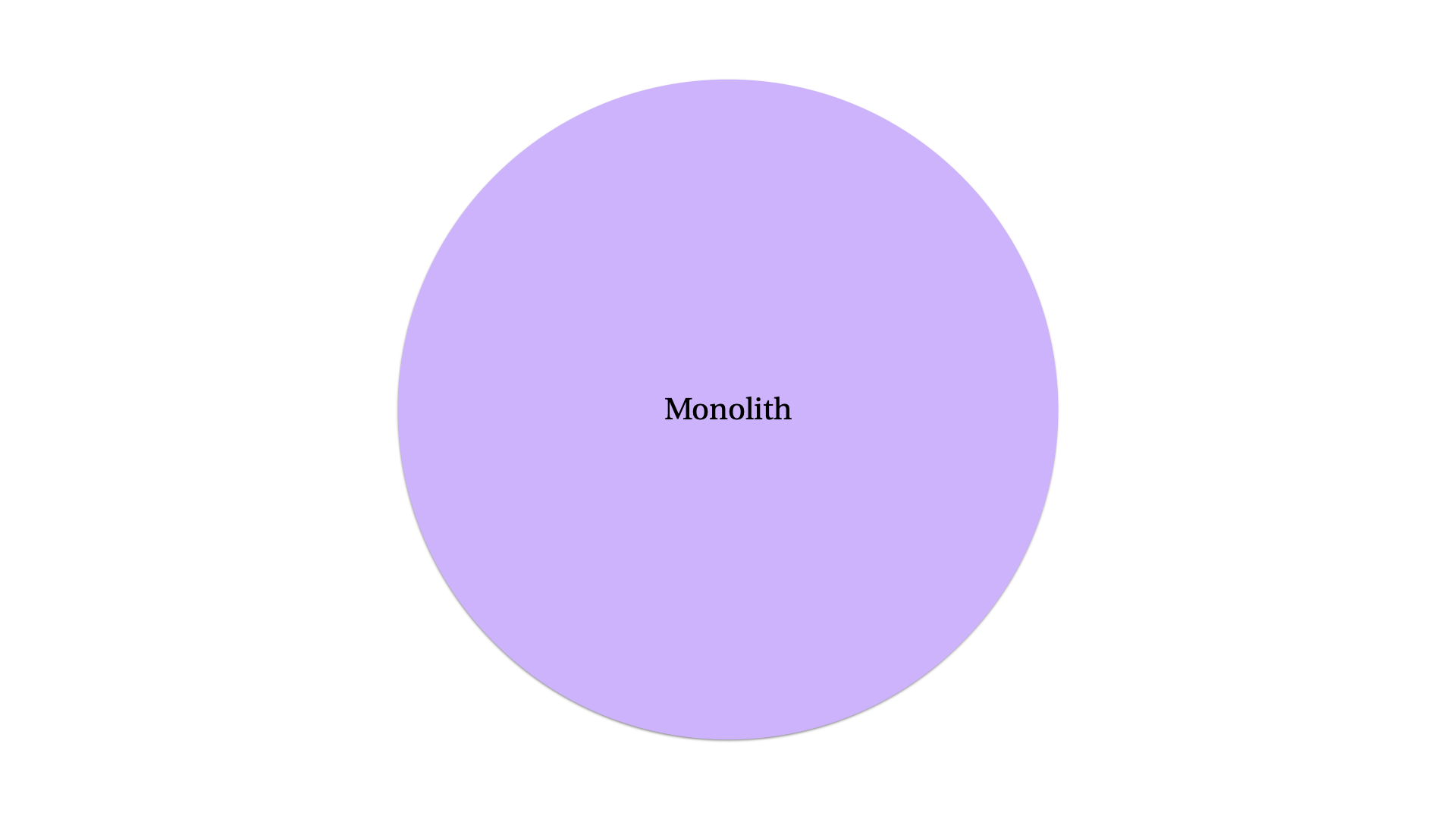
Let’s say that the monolith, and the attendant team, is getting big enough that we’re beginning to consider microservices. We might now ask, “what is the appropriate number of services to split the monolith into?” and that could provoke endless debate even among a team with total consensus that it might need to be split into some number of services.
Rather than beginning with the premise that there is a correct number, we may observe instead that splitting the service into N services where N is more than one may be accomplished splitting the service in half N-1 times.
So let’s bi (two) lithify (rock) this monolith, and take it from 1 to 2 rocks.
The task of splitting the service into two parts ought to be a manageable amount of work — two is a definitively finite number, as composed to the infinite point-cloud of “microservices”. Thus, we should search, first, for a single logical seam along which we might cleave the monolith.
In many cases—as in the specific case that r0ml gave—the easiest way to articulate a boundary between two parts of a piece of software is to conceptualize a “frontend” and a “backend”. In the absence of any other clear boundary, the question “does this functionality belong in the front end or the back end” can serve as a simple razor for separating the service.
Remember: the reason we’re splitting this software up is because we are also splitting the team up. You need to think about this in terms of people as well as in terms of functionality. What division between halves would most reduce the number of lines of communication, to reduce the quadratic increase in required communication relationships that comes along with the linear increase in team size? Can you identify two groups who need to talk amongst themselves, but do not need to talk with all of each other?2
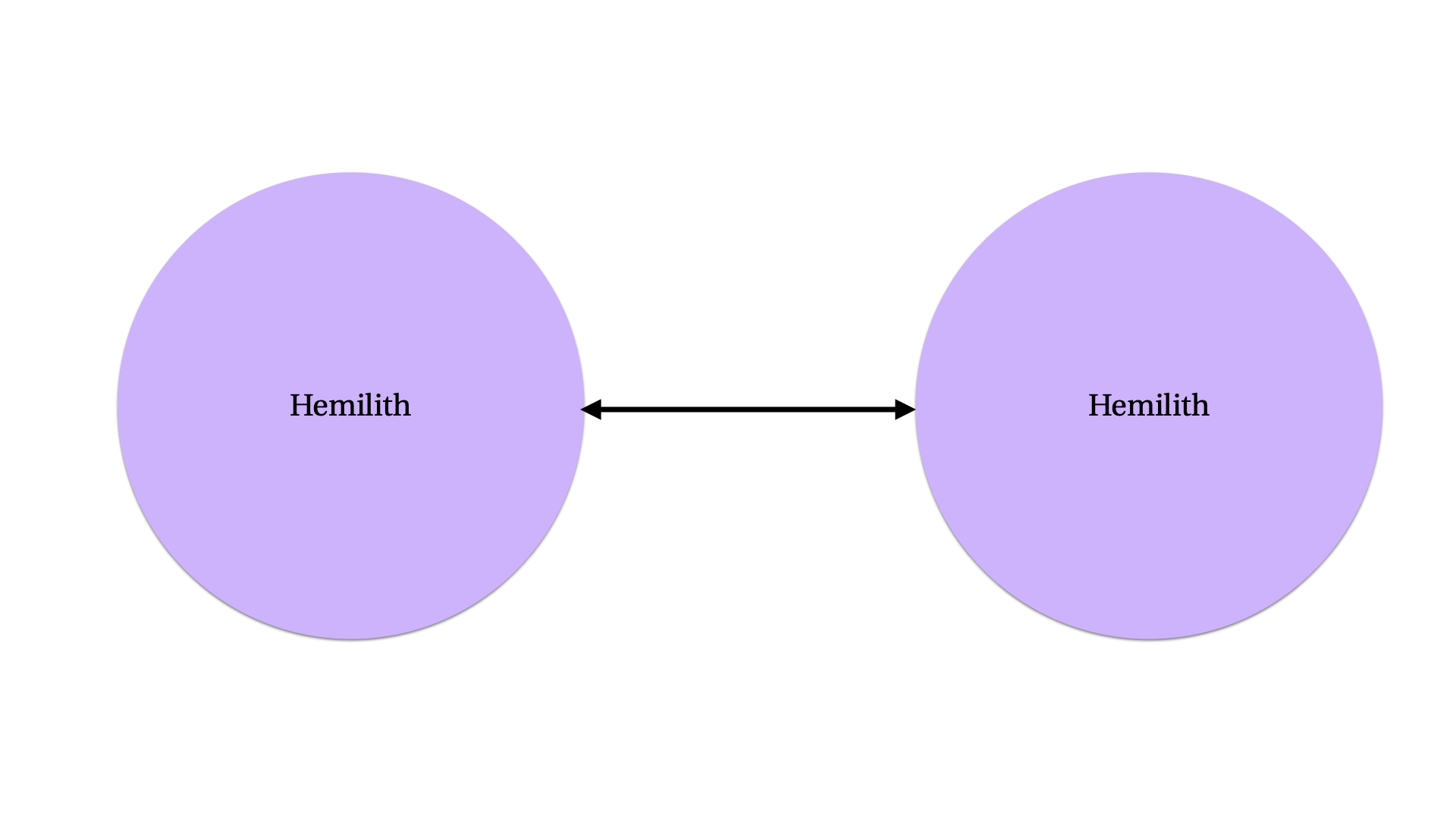
Once you’ve achieved this separation, we no longer have a single rock, we have two half-rocks: hemiliths to borrow from the same Greek root that gave us “monolith”.
But we are not finished, of course. Two may not be the correct number of services to end up with. Now, we ask: can we split the frontend into a frontend and backend? Can we split the backend? If so, then we now have four rocks in place of our original one:
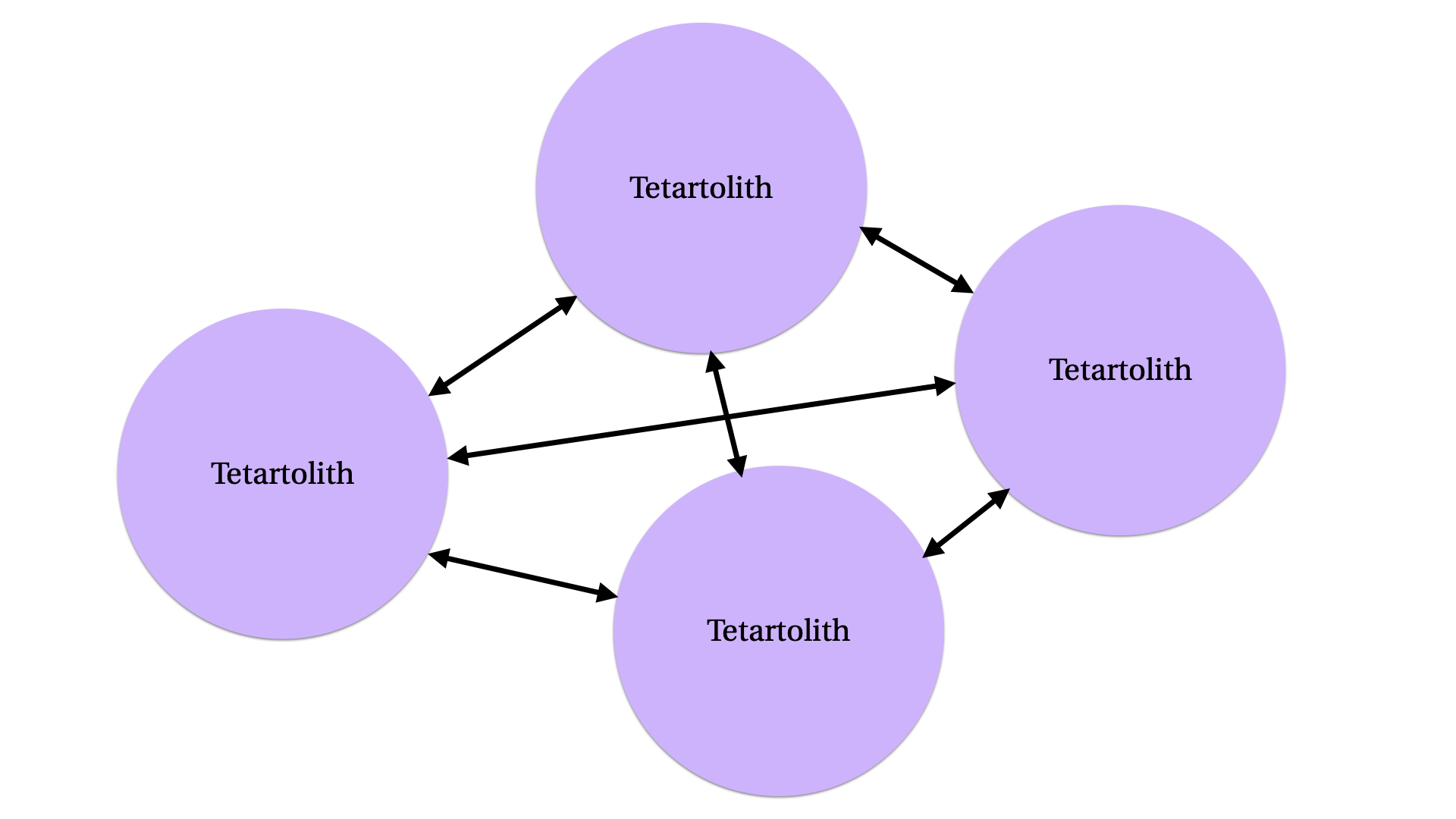
You might think that this would be a “tetralith” for “four”, but as they are of a set, they are more properly a tetartolith.
Repeat As Necessary
At some point, you’ll hit a point where you’re looking at a service and asking “what are the two pieces I could split this service into?”, and the answer will be “none, it makes sense as a single piece”. At that point, you will know that you’ve achieved services of the correct size.
One thing about this insight that may disappoint some engineers is the realization that service-oriented architecture is much more an engineering management tool than it is an engineering tool. It’s fun to think that “microservices” will let you play around with weird technologies and niche programming languages consequence-free at your day job because those can all be “separate services”, but that was always a fantasy. Integrating multiple technologies is expensive, and introducing more moving parts always introduces more failure points.
Advanced Techniques: A Multi-Stack Microservice Environment
You’ll note that splitting a service heavily implies that the resulting services will still all be in the same programming language and the same tech stack as before. If you’re interested in deploying multiple stacks (languages, frameworks, libraries), you can proceed to that outcome via bilithification, but it is a multi-step process.
First, you have to complete the strategy that I’ve already outlined above. You need to get to a service that is sufficiently granular that it is atomic; you don’t want to split it up any further.
Let’s call that service “X”.
Second, you identify the additional complexity that would be introduced by using a different tech stack. It’s important to be realistic here! New technology always seems fun, and if you’re investigating this, you’re probably predisposed to think it would be an improvement. So identify your costs first and make sure you have them enumerated before you move on to the benefits.
Third, identify the concrete benefits to X’s problem domain that the new tech stack would provide.
Finally, do a cost-benefit analysis where you make sure that the costs from step 2 are clearly exceeded by the benefits from step three. If you can’t readily identify that in advance – sometimes experimentation is required — then you need to treat this as an experiment, rather than as a strategic direction, until you’ve had a chance to answer whatever questions you have about the new technology’s benefits benefits.
Note, also, that this cost-benefit analysis requires not only doing the technical analysis but getting buy-in from the entire team tasked with maintaining that component.
Conclusion
To summarize:
- Always start with a monolith.
- When the monolith is too big, both in terms of team and of codebase, split the monolith in half until it doesn’t make sense to split it in half any more.
- (Optional) Carefully evaluate services that want to adopt new technologies, and keep the costs of doing that in mind.
There is, of course, a world of complexity beyond this associated with managing the cost of a service-oriented architecture and solving specific technical problems that arise from that architecture.
If you remember the tetartolith, though, you should at least be able to get to the right number and size of services for your system.
Thank you to my patrons who are supporting my writing on this blog. If you like what you’ve read here and you’d like to read more of it, or you’d like to support my various open-source endeavors, you can support my work as a sponsor! I am also available for consulting work if you think your organization could benefit from more specificity on the sort of insight you've seen here.
-
Denouncing “silos” within organizations is so common that it’s a tired trope at this point. There is no shortage of vaguely inspirational articles across the business trade-rag web and on LinkedIn exhorting us to “break down silos”, but silos are the point of having an organization. If everybody needs to talk to everybody else in your entire organization, if no silos exist to prevent the necessity of that communication, then you are definitionally operating that organization at minimal efficiency. What people actually want when they talk about “breaking down silos” is a re-org into a functional hierarchy rather than a role-oriented hierarchy (i.e., “this is the team that makes and markets the Foo product, this is the team that makes and markets the Bar product” as opposed to “this is the sales team”, “this is the engineering team”). But that’s a separate post, probably. ↩
